Benchmarks results of zlib and zlib-ng running on some AMD and Intel CPUs
Update December 2025:
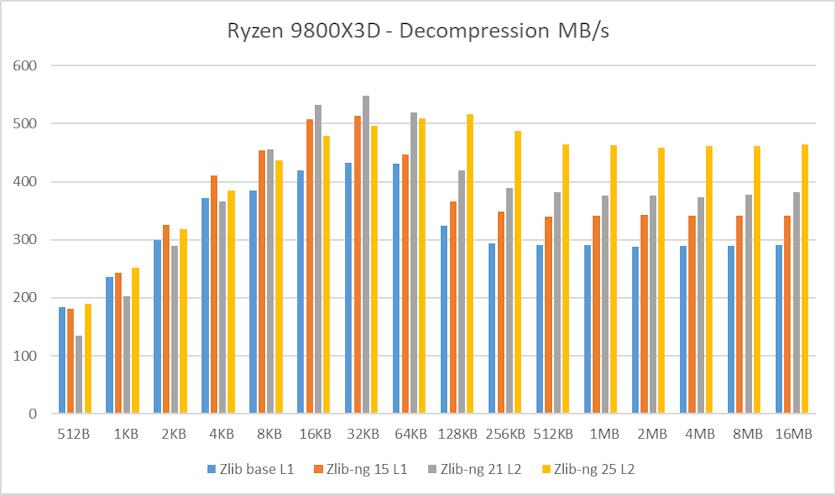
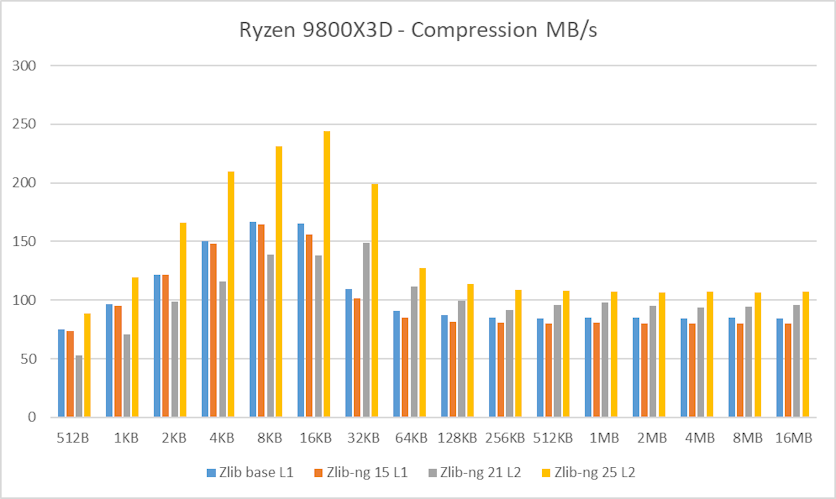
I’ve updated this post with new benchmark results on a Ryzen 9800X3D, including comparisons using zlib, zlib-ng (as previously tested), and the new 2025 release of zlib-ng, which delivers a significant performance improvement..
Back in the 2013 when I began to work on CRM64Pro, I did a quick survey of possible compression algorithms to use. With CRM32Pro, I used UCL (discontinued since 2004) and I wanted to use a newer and portable compression algorithm.
I played a bit with zlib, LZ4, zstd and others but finally, I selected zlib as, at that time, was very portable, much faster than former UCL and well maintained. Also, it is used by libpng which it is included on CRM64Pro and for simplifying the external needed libs, zlib was the easiest solution.
It is true that LZ4 is much faster than zlib. zstd is also faster than zlib and supports parallel decompression streams, something that can not be done with zlib. Note that there is parallel compressor using zlib (pigz) but it is designed as a replacement of the gzip tool.
Well, coming back to the topic, since a few years ago, I have followed the zlib-ng project as it is a compatible replacement of zlib but heavily optimized (in fact, it is a fork version of zlib with several added optimizations).
In 2015, I performed some tests using zlib-ng but the results were not very good, mainly because the source code with SSE4 and AVX2 instructions was not ready for Visual Studio.
Recently, I checked again zlib-ng project and could see that they were working hard and implemented all the optimizations for Visual Studio so I gave it a try.
I did some benchmarks compressing and decompressing “random” but deterministic data blocks of:
|
|
Why so smalls? because in CRM64Pro we are compressing/decompressing small data blocks either for network transmissions or image resources (sprites, buttons, etc.) and hardly its size is greater than a few Megabytes.
I have a few PCs available for performing tests (all with Windows 10):
- Ryzen 2400G
- i7-2600K
- i7-3770
- i7-4960HQ
- i7-10750H
- Ryzen 5900X
- Ryzen 9800X3D
And well, I tested zlib 1.2.11 (from 2017), zlib-ng version from 2015 and the newest zlib-ng from March 2021. They are all compiled with the maximum optimization flags and in 64bits mode.
Compression tests
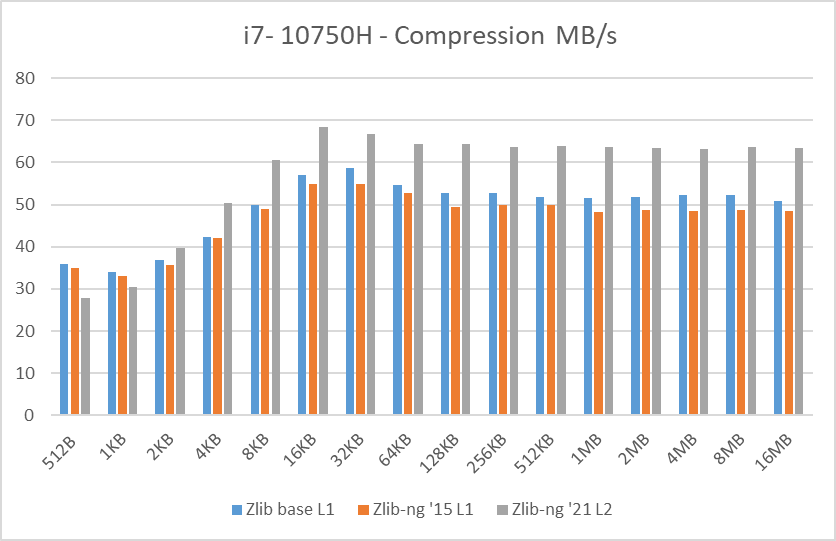
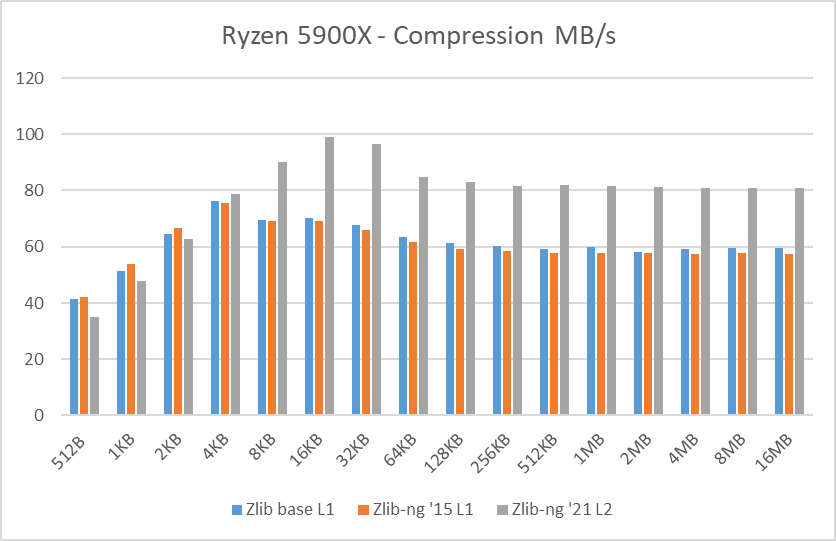
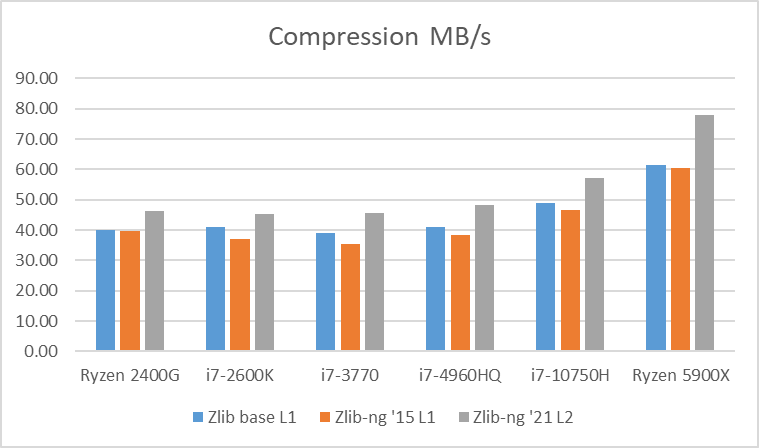 Table 1: Average of compression data blocks speed in MB/s
Table 1: Average of compression data blocks speed in MB/s
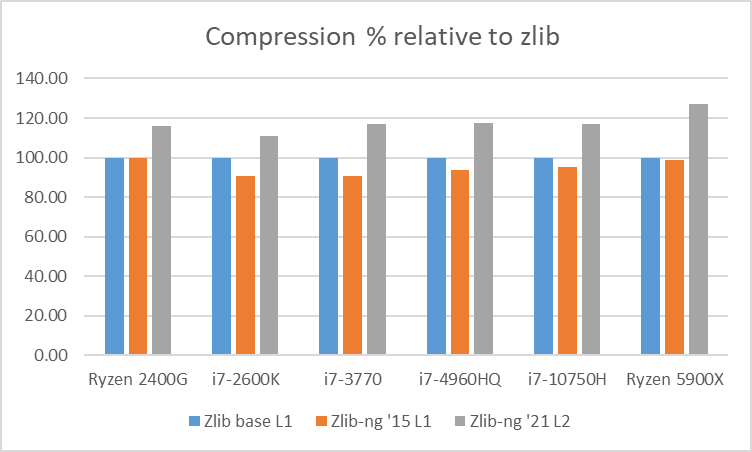 Table 2: Average of compression data blocks speed relative to zlib
Table 2: Average of compression data blocks speed relative to zlib
In these graphs, you can easily see that zlib-ng version of 2015 was a performance regression on all Intel CPUs. AMD CPUs were just a hair slower but in any case, this version is not an upgrade to the standard zlib library.
New zlib-ng version of 2021 is clearly faster. In addition, it is using Level 2 so it compressed the data a bit more, hence it is a win-win scenario. Why am I using Level 2 instead of 1? because Level 1 on zlib-ng does not compress the data (at least the “random” deterministic data I was using) so I had to use Level 2.
The performance increase varies from 11% with the i7-2600K to 27% on the newest Ryzen 5900X so doing an average of the “averages”, we have 17.5% of compression speed increase due to zlib-ng which is fine.
Decompression tests
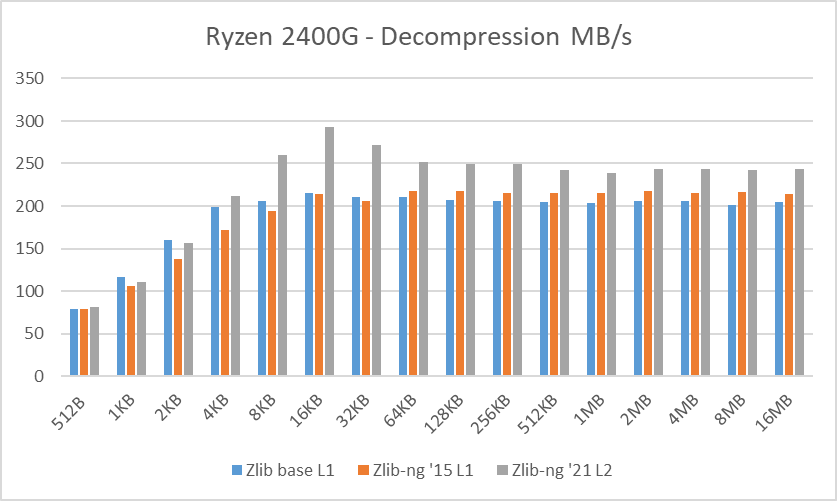
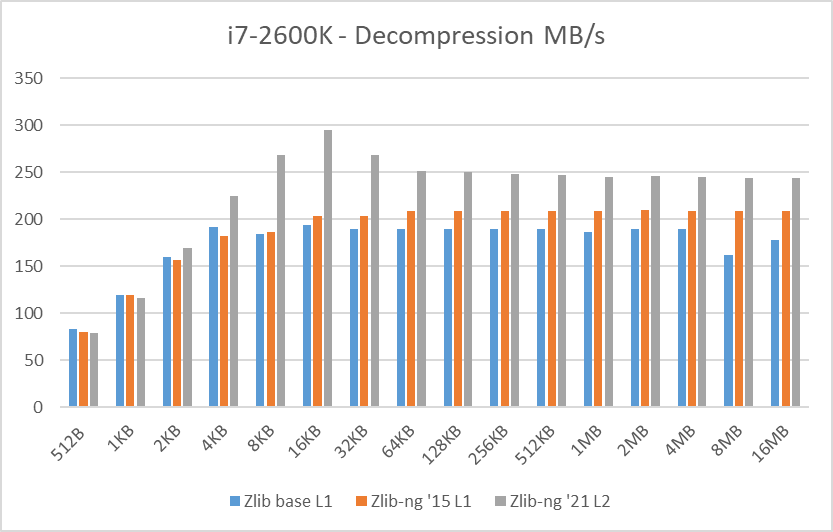
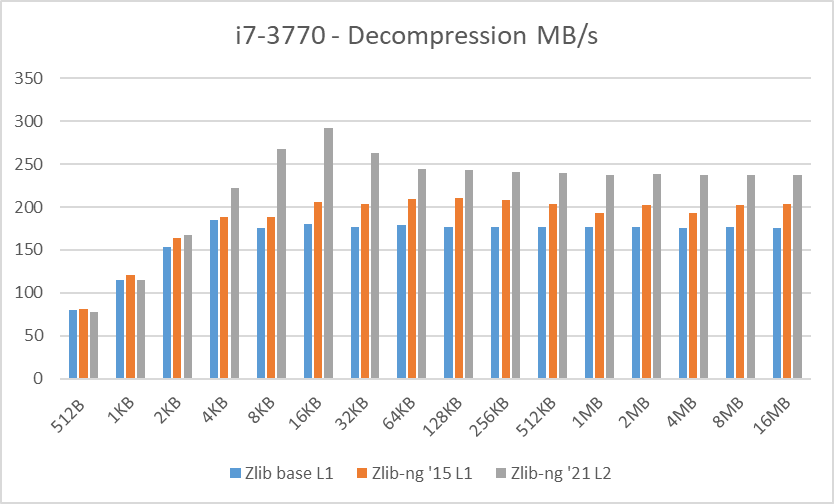
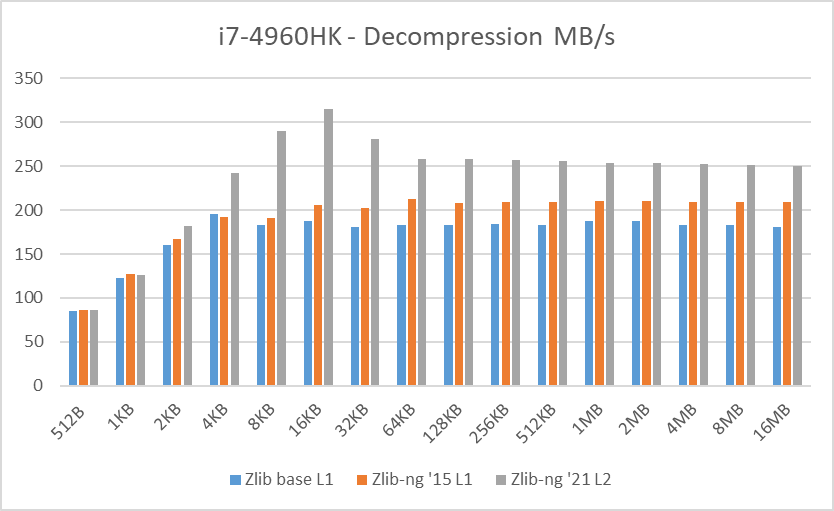
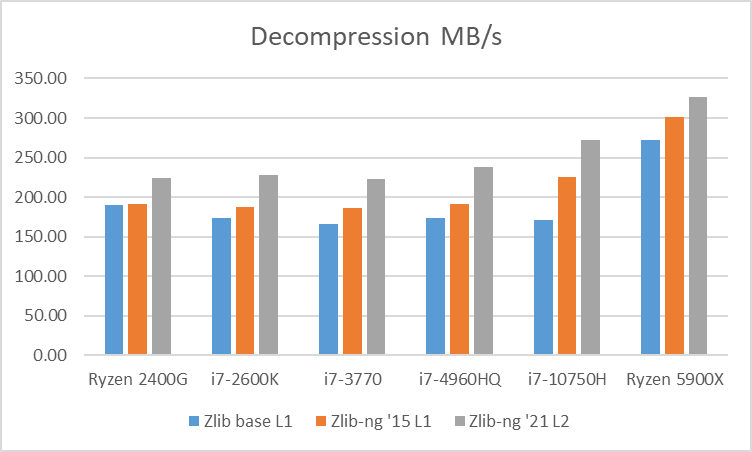 Table 3: Average of decompression data blocks speed in MB/s
Table 3: Average of decompression data blocks speed in MB/s
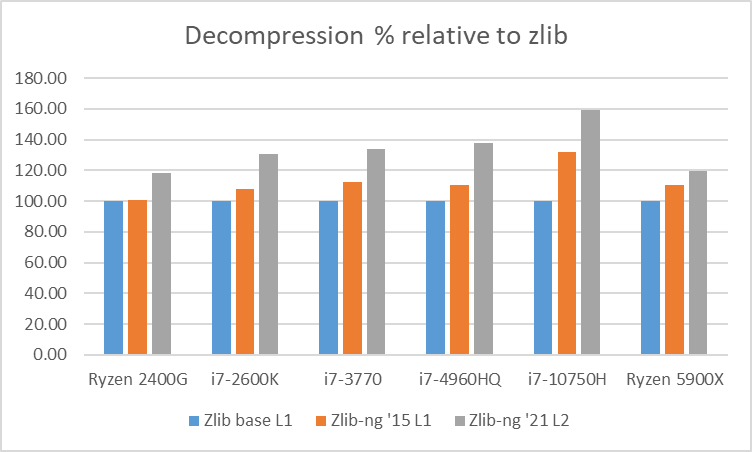 Table 4: Average of decompression data blocks speed relative to zlib
Table 4: Average of decompression data blocks speed relative to zlib
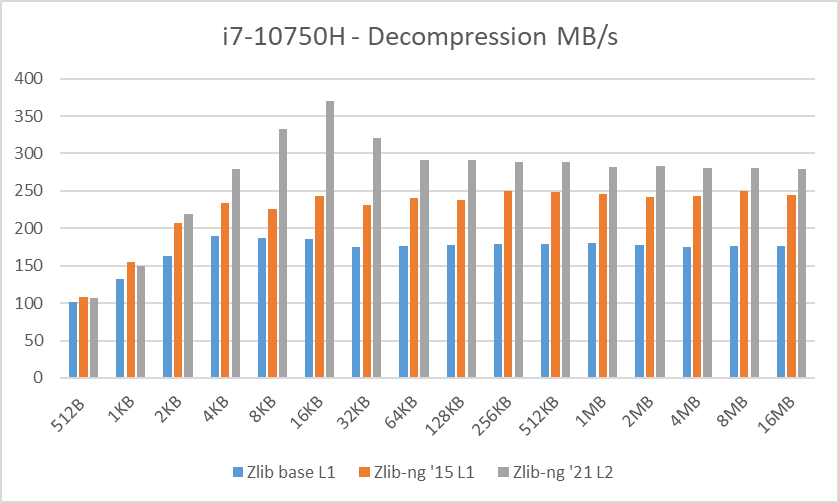
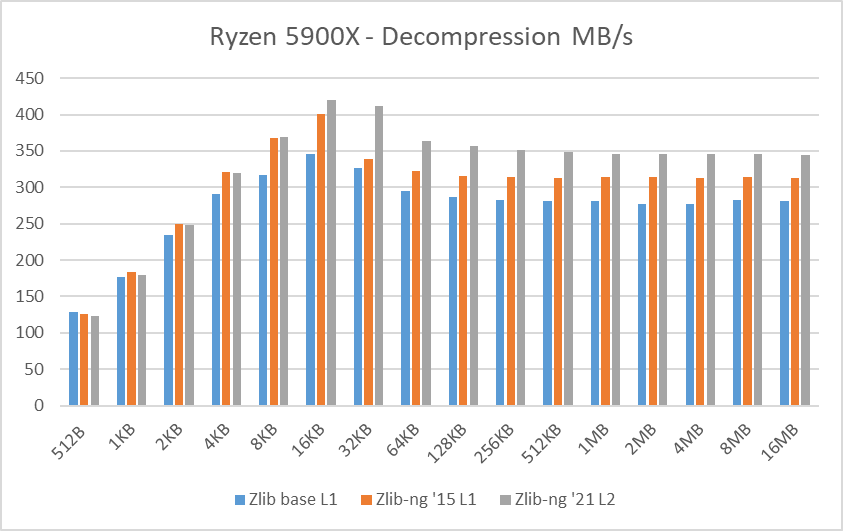
Decompression tests however, showed that zlib-ng version of 2015 had some performance bonus. It seems that Intel CPUs benefit more from these optimizations. But still, the average of “averages” increase is not that great.
And here again, new zlib-ng version of 2021 is clearly faster. The decompression optimizations help more to Intel CPUs than AMD CPUs so thanks to it, they now perform on a similar level. The exception is, as expected, the Ryzen 5900X which is a completely different beast.
In these tests, the performance increase varies from 18% with the Ryzen 2400G to 59% on the i7-10750H so doing an average of the “averages”, we have 33% of decompression speed increase due to zlib-ng which is quite great!.
Conclusions
New zlib-ng version of March 2021 is clearly faster than zlib (on average +17% when compressing data and +33% when decompressing) and also the compression ratio is a bit higher due to the usage of Level 2.
The trend is that newest CPUs with better/wider hardware logic for executing AVX2 code are performing better.
For these reasons, I have replaced zlib by zlib-ng on CRM64Pro starting from v0.970.
It is already tested and everything works fine (as expected) and also faster. It is noticeable using EditorC64 when adding high resolution images. I will release this new version on the coming weeks.
Do you want to give it a try on your CPU? Download below file and test it:
Note: in these tests, you can also see UCL and LZ4 algorithms performance although keep an eye on the compression ratio they get as sometimes they do not compress anything.
Internally, I have developed an application (AlgoSpeed) for checking algorithms performance for compression, encryption, hashing and random number generators so I could select the best ones for CRM64Pro. It needs a bit of “refresh” but I plan to finish it and upload here.
Annex I: individual benchmarks
- Compression results:
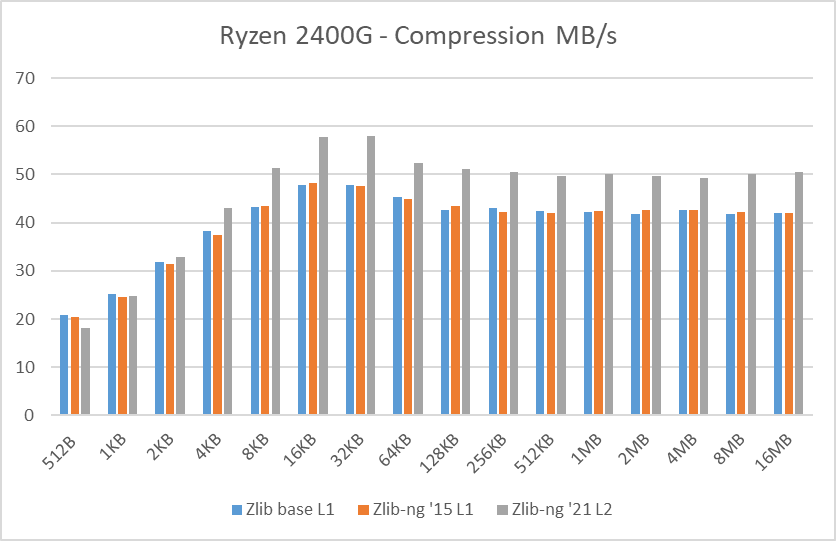
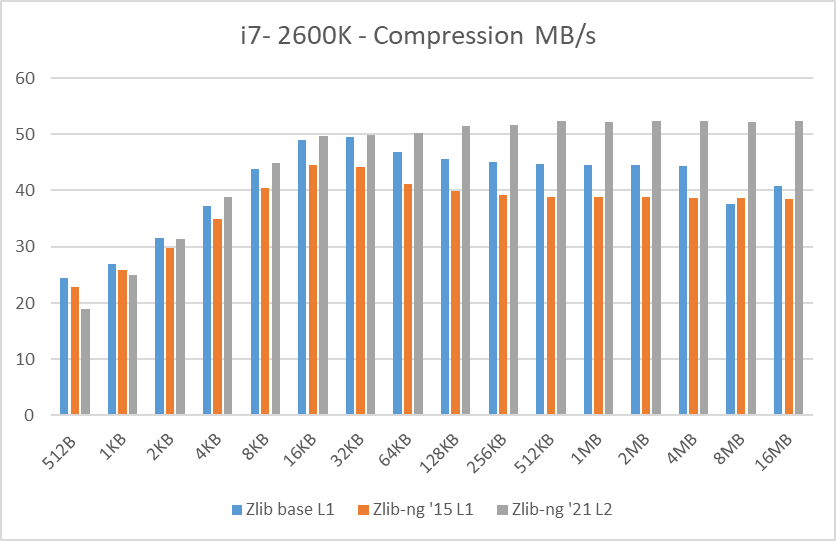
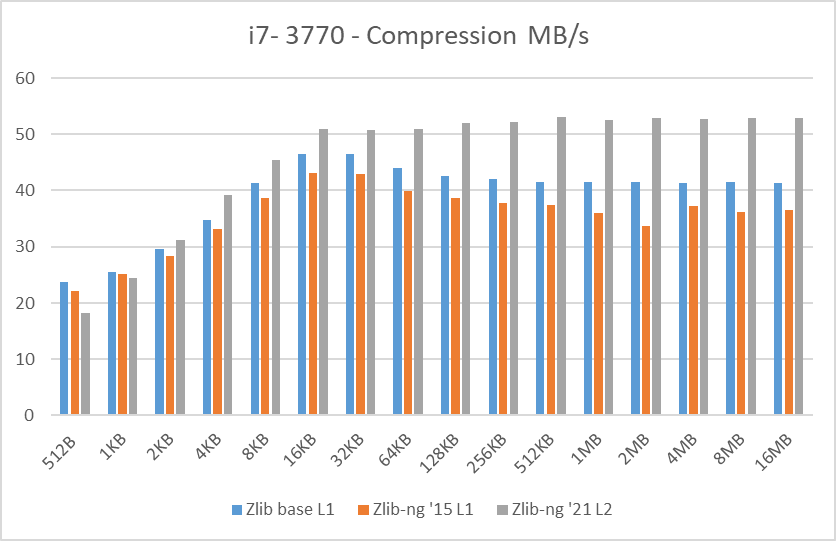
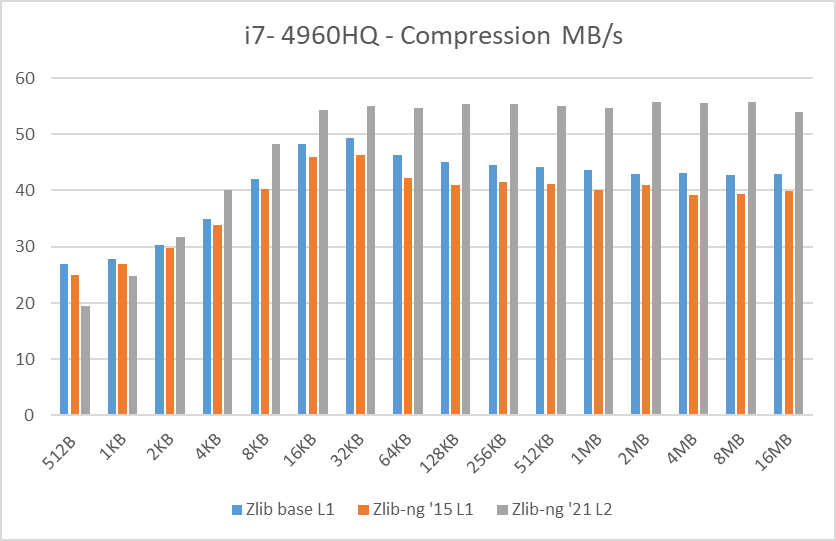
- Decompression results: